Let’s say we have a binary string with 4 bits as \(\textbf{1010}\). When we transmit this message and it is recieved by the reciever, the probability that the bit has changed its value or P(Bit error) = 0.2. Hence, the message or string recieved will have about 20% of it’s bits different then the original message.
One of the solutions to reduce the Bit probability error is to encode the binary string such that transmitting the encoded message reduces the Bit probability error, transmit the encoded message and the reciever can decode the string to recieve the original message with lesser bit probability error. Following is an example of one such coding strategy.
\(\text{R}_\text n\) coding strategy
In this strategy, we repeat each bit in the original binary message n times and transmit that message. While decoding the message, we pick the most frequent bit in the subsequent n-sized subset as the output bit. Here we take n as an odd integer for obvious reasons.
In the above example, our bit string is \(\textbf{1010}\). If we use the \(\text R_\text 3\), the encoded message is \(\textbf{111000111000}\).
After transmitting the message, the binary message could be \(\text{1{\color{red}0}1000{\color{red}0}1100{\color{red}1}}\).
If we choose the bit with maximum freuqency in each 3-sized subset we get,
Hence, the decode string is \(\text{1010}\) which is the same as the original string despite of some errors during transmission. Such a strategy reduces the bit probability error.
In the above example, if we consider a 3-sized subset. The bit is flipped or gives an error after transmission if 2 or more bits are flipped. Hence, the bit probability error for this case can be calculated as follows.
P(2 bits flipped) = \(3 \hspace{0.05cm} \text x \hspace{0.05cm} \text p^2 \hspace{0.05cm} \text x \hspace{0.05cm}\text{(1-p)}\). Here \(\text{p}\) is the bit probability error (0.2 in the above example).
P(3 bits flipped) = \(\text p^3\).
The new bit probability error is P(2 bits flipped) + P(3 bits flipped). Calculating with \(\text p=0.2\). The new bit probability error is \(\textbf{0.104}\) which is less than 0.2.
Limitations
Even though the bit probability error is reduced, it could still be significant. There could still be two bits or more flipped in a 3-sized subset in the above example. Increasing the number n will reduce the bit probability error but in doing so we slow down the message. If we define rate as \(\text{rate}=\hspace{0.1cm}\frac{\text{length of original string}}{\text{length of encoded string}}\). On increasing n, the length of the encoded string increases and so the rate decreases and the message takes more time for transmission.
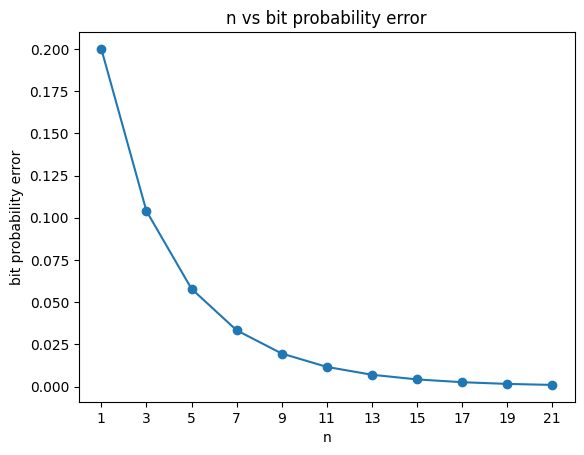
Following is a plot of n vs bit probability error.
from math import factorial as fdef nck(n,k):if (n<k):returnreturn f(n)/(f(k)*f(n-k))# n is number of repeatations of each bit# p is bit probability error when n=1def bit_probability_error(n,p): min_bits = (n+1)//2 prob_sum =0for bits inrange(min_bits,n+1): n_choose_k = nck(n,bits) prob_sum += n_choose_k * (p**bits) * ((1-p)**(n-bits))return prob_sumrounded_off_error =round(bit_probability_error(3,0.2),3)print(f"Reduced bit probability error is {rounded_off_error}")
Reduced bit probability error is 0.104
import numpy as npimport matplotlib.pyplot as pltn_range = np.arange(1,22,2)rate =1/n_rangen_range,rate
plt.plot(n_range,reduced_probability,marker='o')plt.title("n vs bit probability error")plt.xlabel("n")plt.xticks(n_range)plt.ylabel("bit probability error")plt.show()
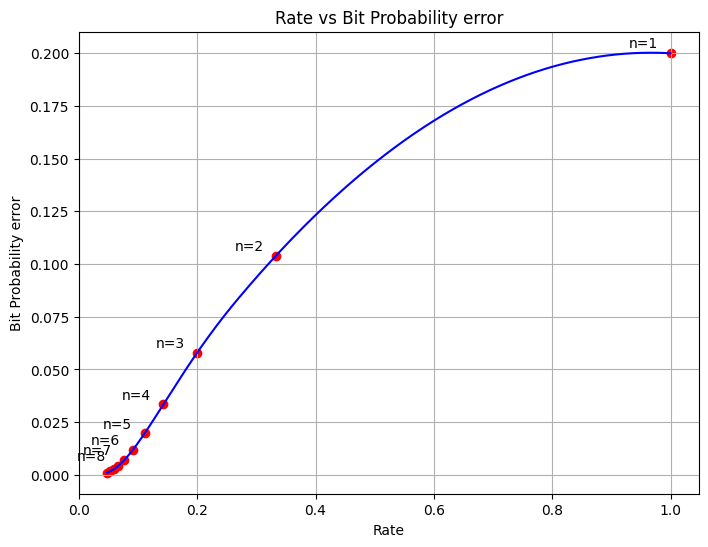
Let’s also plot rate vs bit probability error
from scipy.interpolate import interp1dinterp = interp1d(rate, reduced_probability, kind='quadratic')fine_rate = np.linspace(rate.min(), rate.max(), 5000)smooth_reduced_probability = interp(fine_rate)plt.figure(figsize=(8, 6))plt.plot(fine_rate, smooth_reduced_probability, color='b')plt.scatter(rate, reduced_probability, color='r', marker='o')for i inrange(8): plt.annotate(f"n={i+1}",(rate[i],reduced_probability[i]),textcoords="offset points",xytext=(-30,4),ha="left")plt.xlabel('Rate')plt.ylabel('Bit Probability error')plt.title('Rate vs Bit Probability error')plt.grid(True)plt.show()
This is possibly how Bit probability error varies with rate.
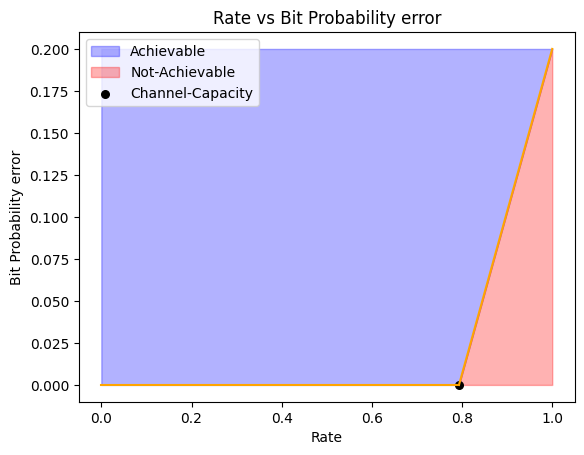
We want to figure out the regions in the plot of rate vs bit probability error which can be achievable. Famous computer scientist Claude Shannon discovered which regions in the above plot are achieveable, that it is possible to achieve atmost a rate C (channel capacity) given non-zero bit probability error where C is given as follows
def channel_capacity(p):return1- (p*np.log2(1/p) + (1-p)*np.log2(1/1-p))def f1(p,c): x = np.linspace(c,1.0,10) m = p/(1-c)return m*(x-c)def plot_achievable(c,p): x1 = np.linspace(c,1.0,10) x2 = np.linspace(0,c,10) y1 = f1(0.2,c) y2 = np.zeros(x2.shape) plt.plot(x2,y2,color="orange") plt.plot(x1,y1,color="orange") plt.xlabel("Rate") plt.ylabel("Bit Probability error") plt.title('Rate vs Bit Probability error') x = np.concatenate((x2,x1)) y = np.concatenate((y2,y1)) plt.fill_between(x, y, max(y), where=(y <=max(y)), color='blue', alpha=0.3,label="Achievable") plt.fill_between(x1, y1, color='red', alpha=0.3, label="Not-Achievable") plt.scatter(c, 0, color='black', label='Channel-Capacity',s=30) plt.legend() plt.show()c = channel_capacity(0.2)plot_achievable(c,0.2)
Hence, as long as we have a non-zero bit probability error no matter how arbitrarily small it is, we can achieve a rate upto Channel-Capacity. Although Shannon discovered that such a rate is possible, but he didn’t tell which encoding strategy from all possible can achieve this. You can further change the parameter values in the following streamlit application.
In the \(\text R_n\) coding strategy, let’s say we take a 4 bit string and we take n as 3. The length of the string increases by \(\textbf {300}\)%. This slows down the message drastically. We can instead use a better encoding strategy called the Hamming code strategy which only increases the length of the string in this example by \(\textbf {75}\)%.
Let’s say our bit string is \(\textbf {abcd}\). We encode our string as \(\textbf {abcdefg}\), where, \(\textbf e=(\textbf {a+b+c})\text{mod}\hspace{0.005cm}2,\textbf f=(\textbf {a+b+d})\text{mod}\hspace{0.005cm}2,\textbf g=(\textbf {a+c+d})\text{mod}\hspace{0.005cm}2\).
Hence, if we take our original message to be \(\textbf {1011}\), our encoded message becomes \(\textbf {1011001}\).
Here, we have increased the length of the bit string by 3. In General, if the bit string length is increased by 2t+1, the number of errors should be atmost t.Since we have increased our bit string length by 3, the number of error bits can go only upto 1. This is one of the limiations of such an encoding strategy.
The idea behind decoding the transmitted message is that, we have a finite set of alphabets \(\text S\), which here is equal to \(\textbf{F2}\) (0 or 1). We generate a set \(\textbf{S}^n\) such that,
We define a code \(\text C\) such that, \(\text C \subset \text S^n\) and \(\text C\) is the set of all codes of length \(\text n\) over alphabet \(\text S\), here \(\text n\) is the length of the encoded message.
Let’s say \(\text v\) is our original message, we encode this message to \(\text w\) and transmit \(\text w\). The recieved message is some \(\text w'\). We find a word \(\text w'' \subset \text C\), such that the hamming distance (d) between \(\text w'\) and \(\text w''\) is minimized. We then decode \(\text w''\) to get \(\text v'\). If atmost \(\text t\) errors occured during transmission and \(\text C\) corrects \(\text t\) errors then,\(\text w''=\text w\) and \(\text v'=\text v\). A code corrects \(\text t\) errors if for every \(\text u \in \text S^n\) there is atmost one \(\text v \in \text C\) such that the hamming distance of \(\text u\) and \(\text v\) is atmost \(\text t\).
One of the main problems of the above method is to find for given \(\text S\),\(\text t\),\(\text n\) a code \(\text C\) of length \(\text n\) over alphabet \(\text S\) such that \(\text C\) corrects \(\text t\) errors and with as many words as possible.