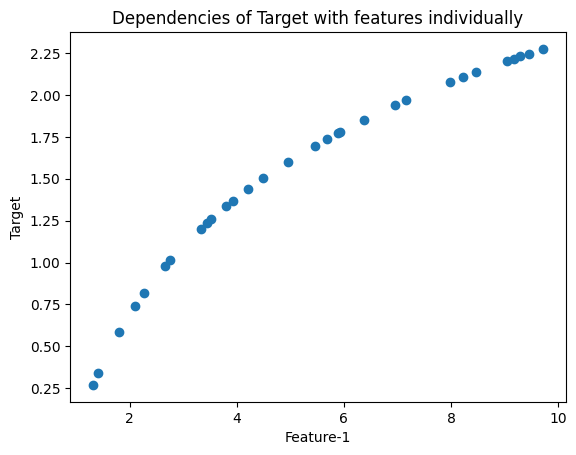
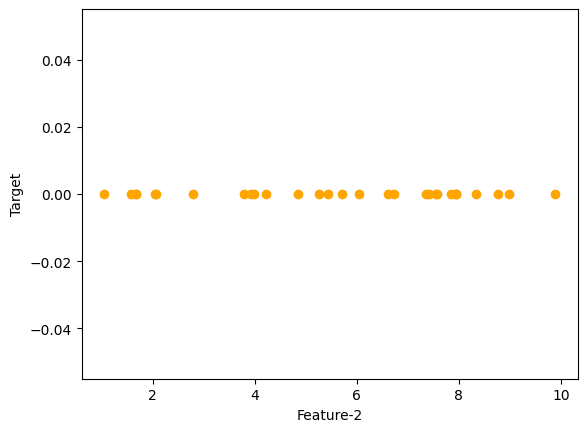
Code
import numpy as np
def joint_prob(val_x,val_y,X,Y):
n = len(X)
count=0
for i in range(n):
if (X[i]==val_x and Y[i]==val_y):
count+=1
return count/n
def mutual_info(X,Y):
n = len(X)
unique_x = list(set(X))
unique_y = list(set(Y))
prob_x = [X.count(x)/n for x in unique_x]
prob_y = [Y.count(y)/n for y in unique_y]
MI=0
for i in range(len(unique_x)):
for j in range(len(unique_y)):
px = prob_x[i]
py = prob_y[j]
jointp = joint_prob(unique_x[i],unique_y[j],X,Y)
if jointp==0:
continue
else:
MI += jointp * np.log(jointp/(px*py))
return MI
X = ["A","B","C","A","B","C"]
Y = ["A","B","C","A","B","C"]
Z = ["A","A","A","A","A","A"]
W = ["A","A","C","A","A","C"]
print(f"Mutual information of X and Y is {mutual_info(X,Y)}")
print(f"Mutual information of X and W is {mutual_info(X,W)}")
print(f"Mutual information of X and Z is {mutual_info(X,Z)}") Mutual information of X and Y is 1.0986122886681096
Mutual information of X and W is 0.6365141682948128
Mutual information of X and Z is 0.0